1. 논문 정보
- 제목: Graph Retrieval-Augmented Generation: A Survey RAG
- 저자: Pengcheng Jiang, et al.
- 연도: 2024
- 링크: arXiv:2408.08921
2. 왜 이 논문을 읽어야 하는가
- 현실 문제: 기존 RAG는 문서 파편화로 인해 여러 문서에 흩어진 정보를 연결하는 "복합 추론(Multi-hop Reasoning)"과 전체 맥락을 요약하는 "전역적 질문"에 답변하지 못하고 할루시네이션을 일으킨다.
- 기존의 한계: 단순히 텍스트를 벡터로 변환해 유사도만 비교하는 방식은 데이터 간의 명시적인 구조적 관계(Entity-Relation)를 포착하지 못한다.
- 핵심 정리: 이 논문은 단순 검색을 넘어 그래프 구조(Graph Structure)를 인덱싱, 검색, 생성의 전 과정에 도입하여 LLM이 데이터의 연결고리를 따라 추론할 수 있는 'GraphRAG'의 통합 프레임워크를 리뷰하고 제시한다.
3. 핵심 요약
이 논문은 비정형 데이터 간의 복잡한 관계를 보존하기 위해 그래프 기반의 인덱싱 및 다단계 검색 아키텍처를 정리한다.

4.기존 방식의 문제점 → 해결 방법 → 동기부여
(문제) 기존 RAG의 병목
- Context Loss: 텍스트를 고정된 크기(Chunk)로 자르면서 문맥적 연결이 끊어짐.
- Weak Reasoning: "A와 B의 공통점은?"과 같은 다단계 연결이 필요한 질문에서 관련 정보를 한 번에 찾기 어려움.
- Noise: 질문과 단어 유사도만 높은 무관한 정보를 검색하여 모델의 판단력을 흐림.
(해결) GraphRAG의 3단계 구성 요소
- G-Indexing (인덱싱): 지식 그래프(KG)나 문서에서 추출한 엔티티 간 관계를 그래프 형태로 구축. 벡터, 텍스트, 구조를 모두 담는 하이브리드 인덱싱 수행.
- G-Retrieval (검색): 단순 검색 대신 그래프 탐색(Path-finding) 활용. 쿼리를 하위 단위로 쪼개고(Query Enhancement), 노드/트리플렛/경로 단위로 정밀하게 검색.
- G-Generation (생성): 검색된 그래프 구조를 텍스트로 변환(Graph-to-Text)하거나 그래프 임베딩을 직접 입력하여 LLM이 구조적 정보를 이해한 채 답변 생성.
설계 논리
그래프는 인간의 지식 구조와 유사하다. 데이터 간의 관계(Edge)를 그래프로 명시적으로 정의하기 때문에, 모델이 정보를 찾을 때 "A는 B와 연결되어 있고, B는 C와 관련이 있다"는 논리적 경로를 따라갈 수 있어 추론의 정확도와 근거(Faithfulness)가 대폭 향상된다.
해결방안 및 구조 상세
: GraphRAG의 전체 프로세스를 그래프 기반 인덱싱, 그래프 기반 검색, 그래프 강화 생성의 세 가지 주요 단계로 분해
Graph-Based Indexing (G-Indexing) 그래프 기반 인덱싱

GraphRAG에서는 다양한 유형의 그래프 데이터를 검색 및 생성에 활용한다. 여기서는 이러한 데이터를 출처에 따라 오픈 지식 그래프와 자체 구축 그래프 데이터의 두 가지 범주로 분류한다.
- Open Knowledge Graphs(오픈 지식 그래프): General Knowledge Graphs 오픈소스 데이터와 그래프) + Domain Knowledge Graphs(학술, 전자상거래, 문학, 의료 및 법률 분야 등의 전문 지식 데이터베이스)
- Self-Constructed Graph Data(자체 구성 그래프 데이터): 그래프 데이터를 직접적으로 사용하지 않는 하위 작업의 경우에 연구자들이 문서 간의 구조적 관계를 모델링(그래프 구축)
인덱싱: 그래프 인덱싱(주어진 노드가 모든 에지와 이웃 노드에 쉽게 접근할 수 있도록 함), 텍스트 인덱싱(그래프 데이터를 텍스트 설명으로 변환) 및 벡터 인덱싱(그래프 데이터를 벡터 표현으로 변환하여 검색 효율성을 향상) - 그래프 인덱싱은 구조적 정보에 쉽게 접근할 수 있도록 하고, 텍스트 인덱싱은 텍스트 콘텐츠 검색을 간소화하며, 벡터 인덱싱은 빠르고 효율적인 검색을 가능하게 하기 때문에 하이브리드 인덱싱 접근 방법이 선호된다
Graph-Guided Retrieval (G-Retrieval) 그래프 기반 검색
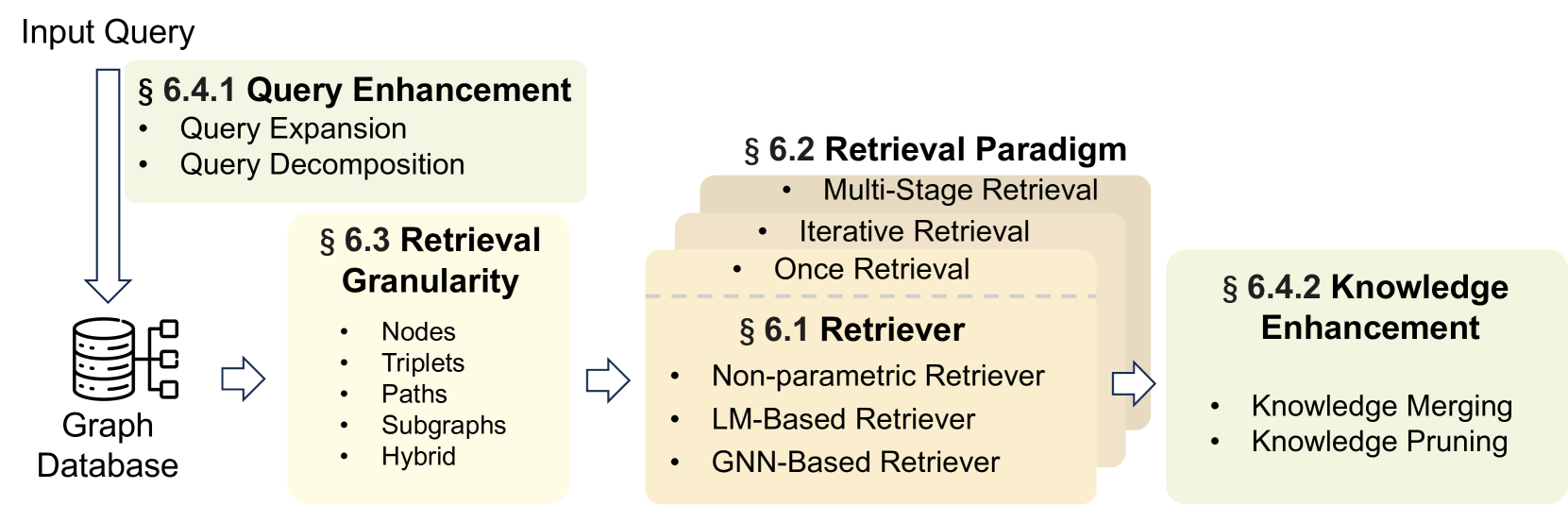
- Retrieval Enhancement(검색 강화)
- Query Enhancement(6.4.1 쿼리 강화): 사용자 쿼리를 보강하거나 하위 쿼리로 나눔
- Knowledge Enhancement(6.4.2 지식 강화): 검색된 정보를 압축하고 집계하거나, 관련성 낮은 정보를 걸러냄
- Retrieval Granularity(6.3.검색 세분성): 작업 시나리오와 인덱싱 유형에 따라 그래프 데이터에서 검색되는 관련 지식의 형태를 다르게 함(노드, 주어-술어-목적어 튜플 형태의 트리플렛, 엔티티 간의 관계 시퀀스를 포착하는 Path)
- Retriever(6.1.리트리버): 다양한 검색 알고리즘 사용
Graph-Enhanced Generation (G-Generation) 그래프 강화 생성
생성 단계로, 검색된 그래프 데이터를 쿼리와 통합하여 응답 품질을 향상시키는 것을 말한다.
적절한 생성 모델을 선택해야 하고, 검색된 그래프 데이터는 생성기와 호환되는 형식으로 변환된다. 생성기는 쿼리 + 변환된 그래프 데이터를 입력으로 받아 최종 응답을 생성한다.
5.방법(파이프라인)
- Input Data: 비정형 텍스트 또는 기존 Knowledge Graph 입력.
- Graph Construction: LLM을 사용해 엔티티(Node)와 관계(Edge)를 추출하여 그래프 생성.
- Hybrid Indexing: 그래프 구조 정보 + 텍스트 설명 + 벡터 임베딩을 결합하여 저장.
- Retrieval Phase: 사용자 질문을 분석하여 그래프 상의 시작 노드를 찾고, 관련 경로(Path)나 이웃 노드를 탐색.
- Context Compression: 검색된 방대한 그래프 정보 중 핵심만 요약 및 정제.
- Augmented Generation: 정제된 그래프 맥락을 프롬프트에 삽입하여 LLM이 최종 답변 도출.
6.실험/결과 요약
- 데이터셋/태스크: 20개 이상의 벤치마크(QA, 지식 그래프 완성, 관계 추출 등) 분석 및 리뷰.
- 비교군: Standard RAG (Vanilla RAG), LLM Zero-shot, 다양한 Graph-based 모델들 비교.
- 확인한 개선 지표:
- Multi-hop QA: 기존 RAG 대비 복합 추론 답변 정확도 대폭 향상.
- Hallucination Rate: 생성된 답변의 근거가 실제 그래프에 존재하는지 확인하는 신뢰성 지표 개선.
7.한계와 실패 케이스
- 높은 비용과 복잡도: 텍스트에서 그래프를 추출(Extracting)하고 관리하는 과정에서 LLM 토큰 비용과 연산량이 일반 RAG보다 훨씬 많이 소모됨.
- 그래프 노이즈(Garbage In, Garbage Out): 초기 그래프 구축 단계에서 잘못된 관계가 형성되면, 검색 시 엉뚱한 경로를 탐색하여 오류가 전파됨.
- 동적 업데이트의 어려움: 데이터가 실시간으로 변할 때 그래프 인덱스를 실시간으로 갱신하고 일관성을 유지하기가 기술적으로 까다로움.
'컴퓨터공학 + HCI > AI' 카테고리의 다른 글
| AI Agent - Tool(도구) 개요와 실습 (0) | 2026.01.06 |
|---|---|
| AI Agent 개요 및 구조 (0) | 2026.01.06 |
| LangChain: RAG 구현에 사용되는 프레임워크 (3) | 2026.01.05 |
| RAG: 검색, 증강, 생성 (0) | 2026.01.05 |
| LM(언어모델) 기본 구조 - 다음 단어 예측(Next Word Prediction) (0) | 2026.01.05 |